Translation of Caffe2 documents in Korean, especially tutorials. The third tutorial is about ‘Models and Datasets’. Here is original Documentation about Models and Datasets.
모델과 데이터셋(dataset)
Caffe2와 딥러닝에 처음 입문하셨나요? 여기서부터 시작해서 다양한 모델과 데이터셋(dataset)에 대해서 자세히 알아보세요!
Caffe2, Models, Datasets 개괄
이 튜토리얼에서는 기존 Caffe모델로 실험을 해 보겠습니다. 다른 튜토리얼에서 모델을 수정하거나 자신만의 모델을 만드는 방법을 배울 수 있습니다. dataset을 수정하거나 생성하는 방법 또한 배울 수 있을 것입니다. 여기서는 모델을 찾는 방법, 필요한 파일들, 그리고 dataset으로 모델을 테스트하는 방법을 배웁니다.
모델 vs 데이터 셋(Datasets)
먼저 dataset과 비교하여 모델이 무엇인지 설명해야겠군요. dataset부터 시작해봅시다. dataset은 데이터의 집합입니다. 이때, 데이터는 그 어떤 데이터라도 가능하지만 보통은 ‘꽃 이미지의 집합’과 같이 관련된 주제(테마)를 갖고 있습니다. 물론, 이런 컬렉션을 동반하려면 몇 개의 레이블이 필요합니다. 이 파일은 각각의 이미지에 대해 말하거나 설명을 제공합니다. 예를 들어, 속(genus)과 종(species)이 될 수도 있고, 일반적인 이름이 될 수도 있고, 외모, 느낌 또는 냄새, 또는 이들의 조합에 대한 것 일 수도 있습니다. 아래 예제에서, Mukane과 Kendule은 이미지 분할과 feature 추출을 사용하여 이미지에서 꽃을 추출하는 방법을 제안하고 있습니다. 메인 이미지를 학습 이미지에서 추출한 다음 분류기가 텍스처 기능을 사용하여 일치하는 이미지를 찾습니다.
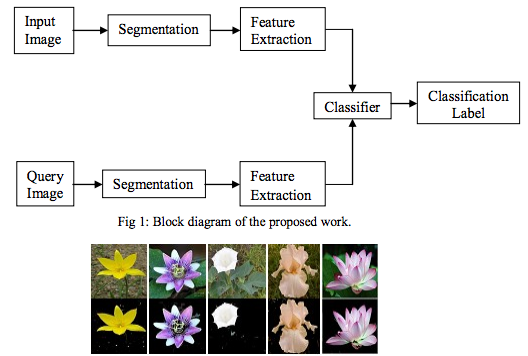
모델은 신경망을 실행시킬 때, 데이터 셋으로부터 만들어집니다. 신경망과 그것을 실행하는 컴퓨터가 데이터 셋으로부터 “배우는 것”을 학습이라고 불립니다. 이것은 데이터 세트의 다른 예제와 유사한 기능과 레이블 간의 공통점을 기반삼아, 이미지의 주요 오브젝트를 인식하는 방법으로 찾을 수 있는 모든 특징을 찾아냅니다. 특정 목적을 위해 설계된 다양한 유형의 신경망이 있기 때문에, 다른 것들보다 더 정확한 모델을 만들 수 있습니다. 위의 꽃 예제를 비롯해 어떤 것을 정확하게 식별할 수 있는 모델을 만드는 데에 있어, 컨볼루션 인공신경망(CNN)을 선택할 수 있습니다. 장소 사진을 식별할 때 같은 방법을 적용합니다. 아래의 interactive한 예제를 보면 네트워크가 공통으로 찾아낸 추출 영역과 그것들이 네트워크 layer에서 어떻게 연결 되어있는지를 보여줍니다.

모델 성능 측정하기
모델을 만드는 데에 있어 가장 보편적인 연습은 정확도(accuracy)와 손실(loss)을 통해 모델의 기능을 측정하는 것입니다.
- 정확도(accuracy): 틀린 것에 비한 맞은 것의 빈도수
- 손실도(loss): 감지했어야하는 것을 감지해내지 못한 빈도수
각각의 case는 이러한 요소들(정확도, 손실)에 대해서 다른 허용 오차를 갖습니다. ID가 꽃인 것에 앱을 적용하는 경우, 92%의 정확도는 매우 놀라운 수준이겠죠. 만약 손실이 많다면, 제대로 작동 가능 할 때까지 다른 각도에서 사진을 찍는 사용자에게 의존할 수 있습니다. 종양을 찾고 있다면, 92%의 정확도는 물론 좋지만 손실이 매우 큰 경우에는 모델을 조금 더 세심하게 작업하고 싶을 것입니다. 의료용 이미지는 비용이 많이 들고 그것을 다른 각도로 찍어달라고 요구하는 것은 쉽지 않기 때문이죠. 이러한 요소들에 대한 평가는 데이터 셋을 가져와 두 부분으로 나누는 방식으로 수행됩니다.
- 첫 번째 부분은 학습에 사용되는, 더 큰 부분입니다.
- 두 번째 부분은 테스트 하는 데 사용되는 작은 부분입니다.
Dataset 나누기(splitting)
어떻게 나눌 부분을 결정하는지, 어떻게 샘플링 되는지, 그리고 라벨이 어떻게 처리되는 지는 또 다른 논의로 다뤄집니다. 80/20비율, 그러니까 80을 학습에 할당하고 20을 테스트에 할당했을 때, 모델이 20%에서 제대로 작동을 한다면 사용이 가능 한 것입니다! “제대로 작동”하는 것을 판단하는 것은 주관적입니다. 데이터 셋의 크기, 라벨, 신경망과 그 구성요소 같은 것을 조정할 수 있고 학습 속도, 탐지 속도, 정확도 같은 요소를 효율적으로 바꾸는 것에 관심이 있을 수도 있습니다.
많은 신경망과 딥러닝 튜토리얼들은 MNIST 필기 데이터 셋을 사용합니다. 이 데이터 셋을 다운받으면 대부분 이미지와 라벨을 각각 학습과 테스트, 두 부분으로 나눈 채로 받게됩니다.
MNIST 학습용 Dataset
- train-images-idx3-ubyte.gz: 학습용 이미지 셋(set) (9912422 bytes)
- train-labels-idx1-ubyte.gz: 학습용 라벨 셋(set)(28881 bytes)
MNIST 테스트용 Dataset
- t10k-images-idx3-ubyte.gz: 테스트용 이미지 셋(set) (1648877 bytes)
- t10k-labels-idx1-ubyte.gz: 테스트용 라벨 셋(set) (4542 bytes)
이 데이터 셋(set)은 60,000개의 학습 이미지와 10,000개의 테스트 이미지, 즉 60/10으로 나뉘어져있습니다. 압축을 해제해서 파일을 열어보는 것을 귀찮게 생각하지 마세요. 물론 그 이미지들을 보기 위해서는 parsing작업이 필요 할 것입니다.. 데이터가 어떻게 수집되고 형식화되는지에 대해 더 많은 정보를 원한다면 이 사이트를 참고하세요.
MNIST tutorial을 참도하면, 이 데이터 셋을 이용해서 CNN을 만들 수 있습니다.
Caffe Model Zoo
Caffe와 Caffe2의 좋은 점 중 하나는 zoo모델에 있다고 할 수 있습니다. 이것은 오픈소스 커뮤니티로부터 제공된 프로젝트들의 집합으로, 모델에 대해 소개하고 그것을 어떻게 만드는지, 어떤 데이터 셋을 사용하는지 등을 제공합니다. 이런 방법으로, 실질적으로 학습을 시키지 않아도 모델만 다운받으면 됩니다. 물론 모델이 어떤 식으로 작동하는지 알고 싶다면 학습용 데이터와 테스트용 데이터를 다운받아 모델의 정확도를 검증해볼 수 있습니다.
커스텀 데이터 셋
자신만의 데이터를 테스트하는 것은 조금 까다롭습니다. 제공되는 모델과 데이터 셋을 자유롭게 다룰 수 있을 때, 다른 튜토리얼에서 그 방법을 다룰 것입니다. 데이터 셋을 합치거나 샘플링하거나, 라벨을 고칠 수 있다는 것에 주의를 기울이는 것이 좋습니다. 라벨에 정보를 더 넣거나 빼고 싶을 수도 있고, 몇몇 학습용 데이터에 라벨을 포함시키지 않을 수도 있습니다. 학습 시에 네트워크가 추측을 하도록 하는 것은 모델 성능 개선의 측면에서 부작용을 야기할 수도 있습니다.(This has an interesting side-effect of actually improving model performance in some cases by letting the network make some guesses during training.) 피사체(feature)를 분류하고 주석을 달 수 있도록 하는 우리의 방식은 컴퓨터의 신경망이 어떻게 작동하는지를 항상 매핑하지는 않습니다. 데이터를 지나치게 많이 맞추면 네트워크 성능이 저하될 수 있습니다.
Caffe 모델 파일
개괄(overview)을 따라서 구체적인 예제로 넘어가봅시다. 모델을 실행하고 작동 방식을 확인하는 데 사용할 수 있는 작은 파일 셋을 살펴 볼 것입니다.
- .caffemodel / .pb2: 주로 크기가 큰 바이너리 파일. 모델을 의미합니다.
- caffemodel: Caffe로부터 온 모델입니다.
- pb2: Caffe2로부터 온 모델입니다.
- deploy.prototxt: 신경망의 디자인을 설명하는 json파일입니다.
- solver.prototxt: 학습 중 사용되는 변수를 설명하는 파일입니다.
- train_val.prototxt:
- readme: 모델이 어떻게 학습되었는지, 어디서 그 모델과 데이터 셋 파일들을 찾을 수 있는지에 대해 정보를 담고있습니다.
예시 모델
caffe2/models on Github에서 사전에 학습된 모델들의 집합을 사용해볼 수 있습니다:
- bvlc_alexnet
- bvlc_googlenet
- finetune_flickr_style
- squeezenet
모델 실행
만약 모델을 학습시키는 과정을 뛰어넘고 싶다면, 사전 학습된 모델 부분으로 넘어갑시다. 모델에 테스트 데이터를 던지고(throw) 어떻게 작동하는지 살펴볼 수 있을 것입니다.